About accuracy in Humanity’s Last Exam...
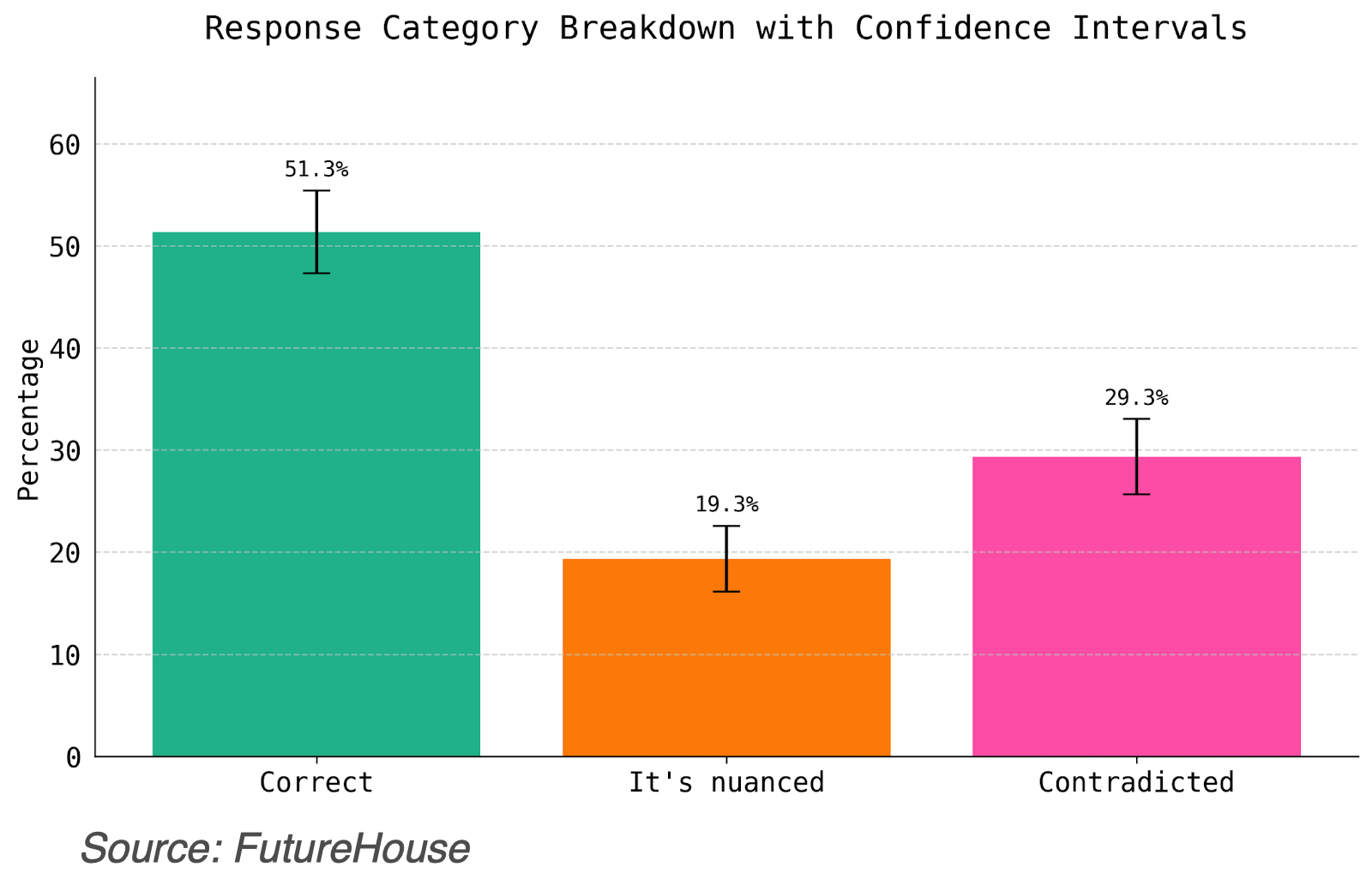
Humanity’s Last Exam was launched as a PhD-level benchmark of 2500 questions across STEM fields, and deliberately designed so that current frontier models would fail. However, researchers at FutureHouse have audited its 321 text-only chemistry and biology questions using their open-source PaperQA2 agent “Crow” and some independent subject-matter experts. Their analysis shows that around 30% of HLE’s official answers are directly contradicted by peer-reviewed literature, around 50% are supported, and around 20% fall into a “nuanced” category where interpretation can sway the outcome.
This high error rate appears rooted in HLE’s question-selection protocol: items were included only if frontier models answered them incorrectly, and reviewers were instructed to spend no more than five minutes checking each rationale. That process favored what the FutureHouse researchers called gotcha or trivia-style questions (such as asking for the rarest noble gas by terrestrial fraction in a particular year) without verifying whether those answers held up under deeper scrutiny. These FutureHouse evaluators uncovered multiple instances where HLE rationales misapplied official standards or overlooked key literature, resulting in widespread contradictions.
To address these shortcomings, FutureHouse has distilled an “HLE Bio/Chem Gold” subset: questions whose answer-reasoning pairs have been rigorously validated by both Crow and human experts. This gold set aims to support more reliable evaluation of advanced language models and offers a template for future benchmarks, either by enforcing deeper factual review or by moving toward literature-grounded assessments.
Personally, I think benchmarks like HLE should prioritize factual integrity over artificial difficulty. Pushing models to their limits is important, yes, even desirable, but it’s counterproductive if the ground truth itself is unstable. True progress will come from evaluations built on well-vetted content, and not from gotcha traps that even human experts struggle to defend.